

At the start of October 2021, Twitter's official account tweeted with a message "hello literally everyone!". This has garnered 3.3 million likes from global users. The reason behind this tweet and such affection is the shut down of other social media services which come under the Facebook umbrella (I mean Meta!). An analysis report generated by The New York Times identified there are 3.5 billion users operating these applications who were affected by the outage. If a company worth billions of dollars can suffer a failure in their systems, literally no one can say they can't. Therefore, today we focus on something that saves us from such outages - fault tolerance with a special focus on the fault tolerance in test automation to identify culprits quickly.
Although the essence of this post is around fault tolerance, we have divided it into three segments as mentioned below:
- What is fault tolerance?
- Fail fast in test automation.
- Fault tolerance in test automation.
- How to build a robust fault tolerance system?
By the end, we would have firmly established the whats, whys and hows of fault tolerance in our day-to-day software testing lives.
What is Fault Tolerance?
Fault tolerance is the "ability of a system or its component (it can be a computer, network, Docker system, cloud cluster, etc.) to recover and continue working without any interruption when one or more of its components have failed." In our personal software development journey, we can say that we have "tolerated" a "fault" when we have designed a mechanism that can help our system from breaking apart. It kind of resembles wearing a helmet while riding a bike but maybe that's just me.
We mostly desire the fault-tolerant system so that we can prevent any disruptions arising from a single point of failure. Every developer and client wants a smooth continuity of their application without any hiccups. It also becomes an extremely important process when we have applications that just cannot afford to go down without warning such as banks and fintech organizations.
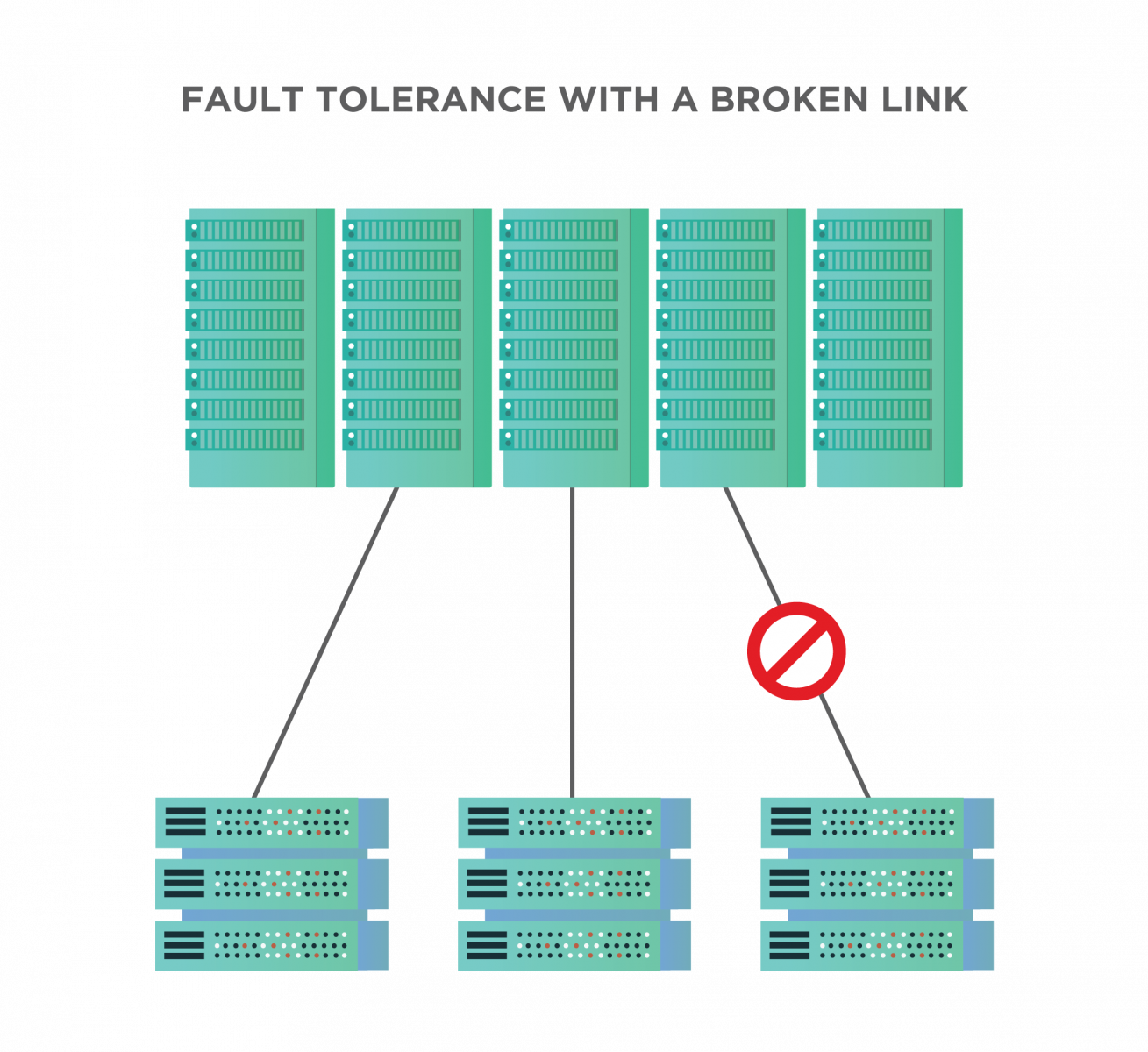
A backup system, therefore, seems like the most desirable way of enhancing fault tolerance until we have rectified and are running again. How this is exactly done depends on the type of system. The following points are important to consider in this regard:
- Hardware systems: Identical or equivalent systems make hardware systems fault-tolerant. For example, in an organization network, we can have more than one server. With such a system if one fails, the other can take over.
- Software systems: When it comes to software systems, we provide fault tolerance by backing up software instances. For example in a Docker system, we can have several parallel containers with mirrored images. When one container fails the other can replace it.
- Power sources: We can use alternate power sources to make the power sources fault-tolerant. So if the main electricity fails, we switch to power generators or invertors.
Bottom line: We need fault tolerance to keep our systems running all the time to have a good reputation in the market.
No user will return to your web application or install your software that keeps crashing frequently. Back in the pure manual testing days, we used to have alerts in our software systems. The system would notify about potential failure and then the technical team would step in and take care of the problem. Modern systems work on agile methodology and have also introduced a concept of testing in production (or production testing).
We observe our system under different conditions on different users and make sure our fallbacks work (the practical implementation of fault tolerance is called fallbacks!). To design this and make sure of it, we make use of backups and redundancies so that while the system is being rectified, it is still online and operating. It does look like a bit of extra money to spend but in the long run, it will be profitable for you.
Fail Fast in Test Automation
We often use the phrase "Fail Fast" in software systems in relation to fault tolerance. It means to assess our system's operation at various points to determine any failure early into the future. This is a design mechanism and a part of fault tolerance. When individual components are fail-fast, we can avoid the chain of failures that can happen in one component and propagate into another. The system should be "ready to fail and come back up again".
So why do we require the "Fail Fast" mechanism?
- As discussed above, a fail-fast mechanism stops the chain of failures in several components of the system.
- Secondly, detecting failure causes is extremely easy when our design mechanisms have fail-fast built into them. This term was originally used in business terms when people used to make business decisions and assess any failures prior to the future. While the processes have changed in IT, the ulterior motives remain the same.
- Fail fast mechanisms save us a lot of costs in SDLC. The earlier a bug is found or a failure avoided, the fewer bucks we need to spend on its correction.
- Fail fast mechanisms in fault tolerance also help us in saving software entropy. It means preventing our code from rotting down when we debug it later. The quick notification and detection of failures help keep the code fresh.
Apart from the fail-fast design, you will sometimes encounter similar terms such as fail-stop, fail-safe, fail silently, etc. All those work on providing a design mechanism to work better against failure. However, they cannot be directly associated with fault tolerance and hence we have omitted it from this post. If you are interested in these designs, Wikipedia would be your best friend!
Fault Tolerance in Test Automation
Now that we know about what fault tolerance is and how important it is to be in our software design mechanisms, we need to take it up a step ahead and dissolve it into test automation. Fault tolerance is a concept of knowing that faults can just be "tolerated" and cannot be completely eliminated by any team or any organization. All we can do is maintain our system at a particular level and determine a maximum level of tolerance which, in professional terms, is also called a failure threshold (or our threshold for failure).
It's very easy to determine the failure threshold. We just need to sit back and decide two things:
- How much experience do our teams have working on automation? - Because experience will be directly proportional to the time they take in resolving bugs.
- How much were we able to afford in the past? - Because past is our greatest teacher.
Once you answer these two questions, you can declare a threshold value and let all your teams know about it.
The difference between failure threshold and fault tolerance is very subtle though. Fault tolerance is a design where we create a safety net. Even though we get failures, we quickly start resolving them. Failure threshold tells us if there is something seriously wrong with our test suites or not. Once we reach this threshold, we don't need to see fault tolerance. Just stop, look back and retrospect all the cases that had executed and those which will be.
Consider a threshold of 15% in my test suite that contains 100 tests for now. A failure threshold of 15% indicates I can afford only 15 test cases to fail in my suite. I don't really care if this happens midway or quarter way or which way. Even if the first 15 test cases fail, I need to stop and look at my suites again. In simple words, I just look at my threshold value and not how many tests I have executed so far.
How to build a robust fault tolerance system?
After discussing the what and why of fault tolerance in the system, the last thing we need to know is how to build one. In the introduction of this post, we discussed how a fault tolerance system depends on the system you are building. There is no step-wise process to create one.
So let's say you have a server serving your millions of clients and suddenly a trojan crawls inside it. Now your application starts responding abruptly to the client's request. What could be the most logical scenario for a fault-tolerant system? A backup server indeed!! Not that expensive though but one that can keep us running for a few hours.
In another scenario, we can take software in which we have a fault tolerance and failure threshold built inside. Cloud-based test automation tools handle such a situation. They generally have a system to define rules and logic to stop test execution when the threshold is crossed. For example, Katalon does provide a feature for the testers to declare a failure threshold for the suite. You can also do it manually but then when you have automation, why bother working so hard.
There's more to learn!
Alright! So we hope that this post has walked you through the concepts of fault tolerance and created a foundation for more complex concepts in the same domain. But you need to have a good grip on automation and the programming methods that can help you understand these tools that help us create a fail-safe system. We, at ToolsQA, have created a sequential series of chapters for your favourite software that can help you in being a good QA engineer. Hope to see you there!






