


This blog is to discuss the real time data import from production to lower environment. Synthetic data creation in Test Data Management would be covered in next blogs.
Let’s think in the insurance industry on testing steps to create one scenario in calculating the base commission.
- Agent created policy with policy holder
- Policy holder changed from recurring payment to regular payment mode
- Policy holder canceled the policy after 1 month. Policy terminated.
- The agent spoke to policy holder and reinstated in regular payment mode.
- Post 2 months, Agent convinced Policy holder to change to recurring payment mode for his better commission.
- Policy holder accepted and he added his family members in the policy.
- Policy and Plan structural changes happen in backend.
Do we think to create test data in manual way to recreate the steps (without production data). We have the below constraints.
- Effort and schedule
- Data integrity. Test efficiency and effectiveness to ensure the data quality to unearth the defect or scenario to get passed.
- Require domain knowledge.
- Business sign-off / Technical sign-off before using the data.
These challenges will be covered by using production data in lower environments and data quality would be 100%.
But there is constraint still. We have compliance standards in Banking, insurance industry to use production data in lower environment. No organization would be allowed due to stringent compliance regulations and security concerns. There are many customer person identifiable information – PII fields (shouldn’t be disclosed) but not limited to below list
- Firstname
- Social security number
- Government ID
- Date of birth
- Address
- Medicare ID
- Credit Card number
- Disease details
We have test data masking solutions to solve the challenge and production data can be imported to lower environments after masking sensitive fields in the staging layer.
This blog will walk-through the test phases and activities required to implement the test data masking. Let’s start with the TDM architecture diagram.
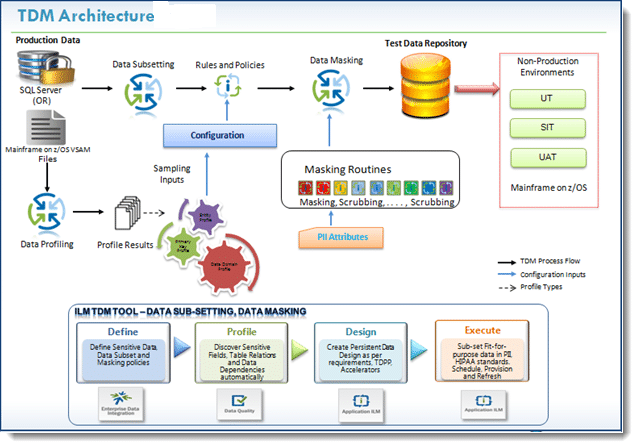
Common challenges in Test Data Masking:-
- Maintaining the consistency of the data in the masked element column: The masking algorithm will always result in the same value for a given value. Ex: If Krishna is masked to Jeya using the algorithm, the result will be Jeya at all the places that Krishna is encountered.
- Retaining the length and Data types: As the masking happens at the database level, Data types should be carefully observed.
- Ability to perform parallel testing and compare against the production data during critical product releases and/or troubleshooting of a production bug fix: A well-defined exception process should be in place to handle these scenarios where real data is needed in the Test regions.
- Masking of DOB will affect rate and age calculations: - Testing regions will be populated with variety of criteria data that will facilitate all the necessary testing requirements. A detailed solution should be in place to handle the rate and age calculations and shouldn’t affect the testing integrity.
Implementing of TDM in phases
Phase 1: Requirements and Analysis.
This document captures the information necessary for the Implementation of Data Masking and Sub setting.
- Application Details: Various sensitive data elements present, upstream and downstream systems with information about the sensitive elements being exchanged are to be highlighted as below.
- Any transformation on sensitive data elements.
- Any encryption on sensitive data elements.
- Any special functions/ processing on sensitive data elements.
- Upstream and downstream impacted on sensitive data elements.
- Impacted web service / XML / flat file on sensitive data elements.
- Invocation method (batch/ real time/ event based / on demand) on sensitive data elements.
- Environment Details: Information specific to Application environments such as Data Sources, Refresh process, Data Volume and Data Model are captured.
- Sensitive Data Scope: Table and Column level details of the sensitive elements are captured.
- Details of primary key, foreign key
- Usage of column in business processing.
- Access to Source and Target databases are established.
- Requirements are analyzed to verify the completeness of the Sensitive fields identified. Various data injection points are captured and analyzed.
Phase 2: TDM Design
- Source and Target Database connections are established and tested using the Tool.
- Initial Sub-setting criteria are captured and analyzed.
- Data Subset, Masking rules and Workflows are defined as below.
- Randomize, Sequence from Range, LOV, Seed, dates
- Shuffling, Substitution and Nulling
- Blurring, Selective Data Masking
- Fill down formulae
- Sizing of the TestData Repository is identified and obtained.
- Implementation design specific to the application is created.
- Final List of Sensitive Elements and DataSub setting criteria are published.
Phase 3: TDM Implementation
- Informatica configurations are established.
- Mappings and Workflows creation based on the identified sensitive elements.
- Initial execution of Workflows in TDM Workspace.
- Unit testing of the data masked in the TDM Workspace.
- Test Data Repository is seeded with the masked data based on the finalized Sub setting criteria.
Phase 4: Data Validation
- Application testing teams are mobilized to perform data and application validation with the masked data.
- Data from the Test Data Repository is pushed into an identified Test region of the application.
- Identified defects are analyzed and fixed.
- Test Data Repository is approved and signed off by the Testing teams.
Phase 5: Deployment and Closure
- Data from the Test Data Repository is moved into the remaining Non-production regions of the application as a part of the Deployment process. This completes the Risk mitigation process of the Test regions for that application.
- The availability of Test region is an important aspect for this phase. Timing the deployment in accordance with the on-going application activities is necessary for timely completion.
- Change in the Test Data Request process will be communicated to the application testing and development teams.
Phase 6: On-going Post Delivery Maintenance and Support
- Post Delivery Support is provided to the Application and Testing teams. This involves the below tasks.
- Test Data Repository Management.
- Test Data Request handling.
- Test Data Repository clean up and refresh based on the key releases in the application and its needs.
- Enhancements to the Informatica Workflows and Mapping due to the Application related changes to the database.
Implementation Challenge in TDM
Member ID is the ID formed by First name + DOB + Plan code + Plan issue date. This is the key field for any policy holder and with Agent, ID to identify the base commission on policies brought to the organization by an agent. Base commission is the base component and will determine the advancing, hold back values for the agent. This member id is applicable for new policies and existing policies.
When we are masking and desensitize the first name and DOB, it will impact the member ID vastly for existing policies as these policies should be referred to historical data for base commission charge back / reversal transactions.
We had two options and project team adopted the option #2 due to budget and effort constraints.
- Built detailed solution not to impact and keep the data integrity for member id throughout the application but effort will be huge
- Testing team to use the new policies as this constraint is not applicable for new policies as it won’t need to refer to the historical data.
Tools for the TDM implementation:-
- Informatica ILM TDM, TDG
- IBM Optim
- CA Test Data Manager (formerly known as GridTools Datamaker)
- BizDataX
- Delphix
We can see database masking and mainframe file data masking in next blog.
Recent trends are Data as a Service (DaaS), Test data management in cloud and could be seen in upcoming blogs.






